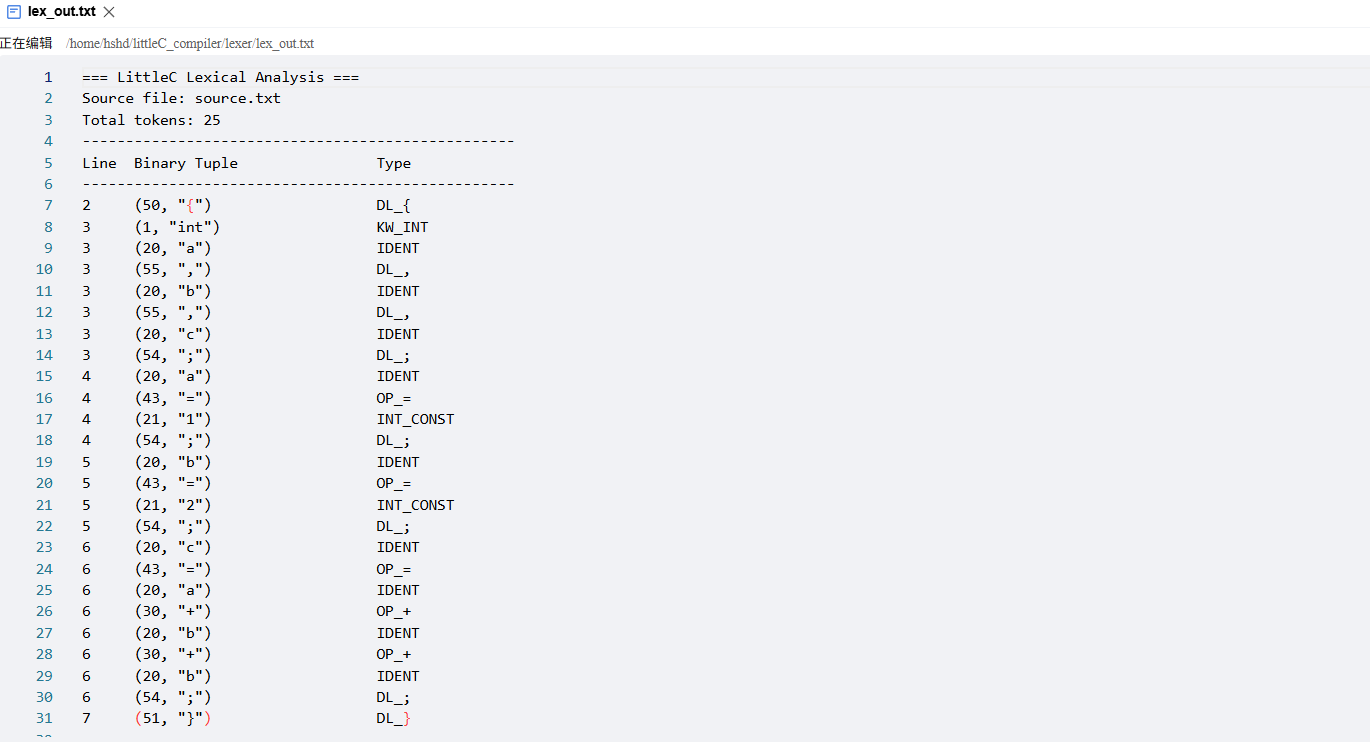
词法分析是编译的第一阶段,负责将源代码的字符流转换为等长二元组形式的 Token 序列。 分析器从左到右逐字符扫描源程序,根据构词规则识别出有意义的最小语法单元,同时记录行号用于后续错误定位。
① Token 分类与编码方案
LittleC 中所有合法词素被分为 5 大类,每个 Token 用 (类型编码, 词素字符串) 的等长二元组表示:
| 分类 | 编码范围 | 包含内容 | 示例 |
|---|---|---|---|
| 关键字 | 1 ~ 11 | int, bool, if, then, else, while, do, read, write, true, false | (3, "if") |
| 标识符 | 20 | 字母/下划线开头,≤8 字符,不区分大小写 | (20, "count") |
| 整常数 | 21 | 纯数字串,≤8 位 | (21, "42") |
| 运算符 | 30 ~ 44 | + - * / > >= < <= == != || && ! = := | (35, ">=") |
| 分隔符 | 50 ~ 55 | { } ( ) ; , | (54, ";") |
② 核心扫描流程
词法分析器采用单遍从左到右扫描策略,维护当前位置指针 pos 和行号计数器 line,通过字符分类跳转到不同的识别分支:
词法分析器核心流程
Pseudocode
函数 tokenize(源代码字符串 src) → Token列表:
pos = 0, line = 1, tokens = []
while pos < src.length:
跳过所有空白字符(遇 '\n' 则 line++)
c = src[pos] // 取当前字符
// ── 跳过注释 ──
if c == '/' 且 next == '/': // 单行注释
跳到行末, continue
if c == '/' 且 next == '*': // 多行注释
向前扫描直到找到 "*/"(未找到则报 E04 错误), continue
// ── 识别整常数 ──
if c 是数字 [0-9]:
贪心读取连续数字 → word
if word.length > 8: 报 E03 错误
tokens.添加( (21, word, line) )
continue
// ── 识别标识符 / 关键字 ──
if c 是字母 或 '_':
贪心读取 [a-zA-Z0-9_] → word
if word.length > 8: 报 E02 错误
word = 统一转小写 // 不区分大小写
if word 在 关键字哈希表 中:
tokens.添加( (关键字编码, word, line) )
else:
tokens.添加( (20, word, line) ) // 标识符
continue
// ── 识别双字符运算符(优先匹配长串) ──
if c+next ∈ { ">=", "<=", "==", "!=", "||", "&&", ":=" }:
tokens.添加( (对应编码, c+next, line) )
pos += 2, continue
// ── 识别单字符运算符 & 分隔符 ──
pos++
switch c:
'+','-','*','/','>','<','!','=': 添加对应运算符Token
'{','}','(',')',';',',': 添加对应分隔符Token
default: 报 E01 错误(非法字符)
return tokens- 最长匹配原则:双字符运算符(如
>=)优先于单字符(如>+=),通过向前看一个字符(peek)实现。 - 关键字与标识符的区分:先按标识符规则贪心读取整个单词,再到关键字哈希表中查找;命中则是关键字,否则是标识符。
- 大小写不敏感:所有标识符和关键字统一转小写后再比对,
INT、Int、int均识别为关键字。 - 注释处理:单行注释
//跳到行末;多行注释/* */跨行扫描,未闭合则报错。 - 模块化设计:词法分析封装为
Lexer类,对外仅暴露tokenize()接口,后续语法分析模块直接调用,无需重复读文件。